
Description
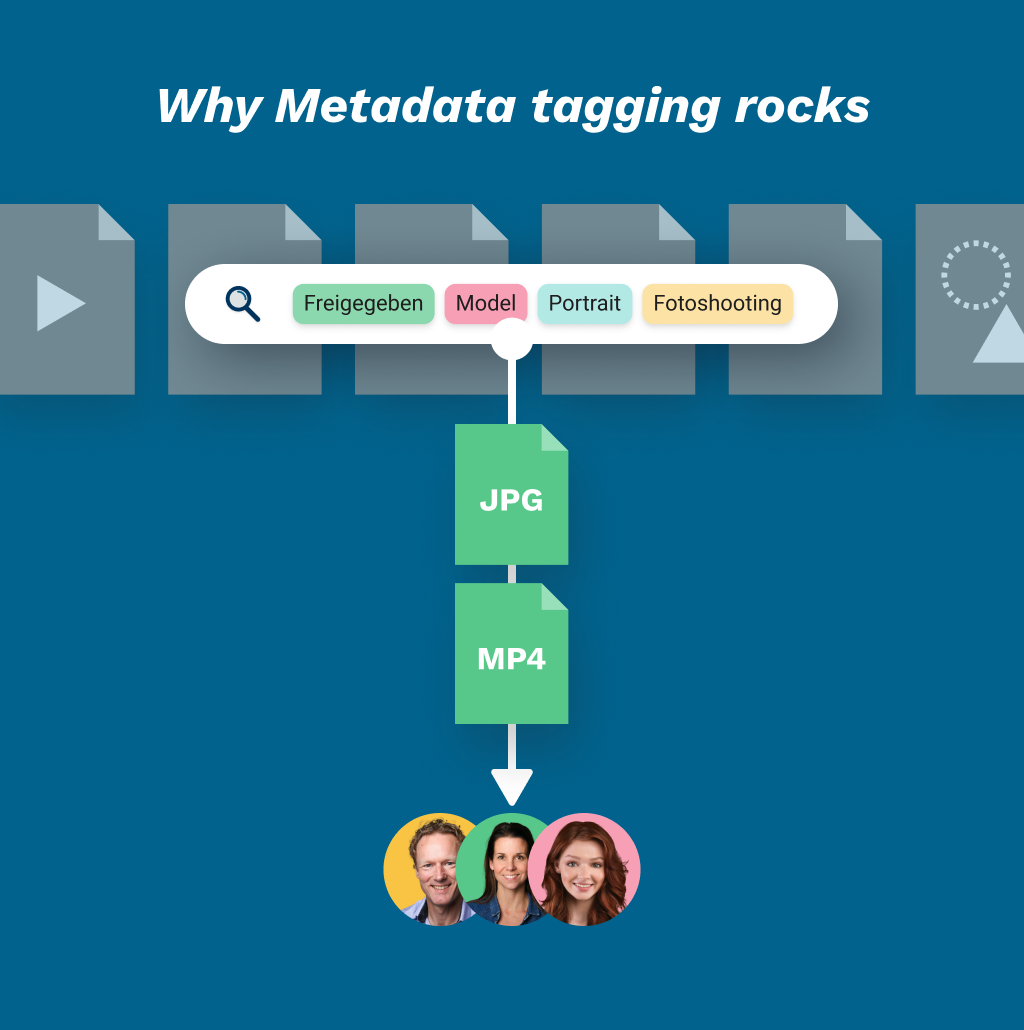
Our Metadata Tagging Automation for Documents service uses cutting-edge Natural Language Processing (NLP), Optical Character Recognition (OCR), and Machine Learning models to turn raw content into structured, searchable knowledge. Whether your documents are PDFs, scanned images, Word files, blog posts, or legal contracts, we build a tagging pipeline that automatically detects topics, entities (names, places, products), taxonomy labels, and sentiment. We support domain-specific classifiers for legal, financial, medical, or educational datasets, trained using spaCy, AWS Comprehend, Google NLP API, or custom transformers. Extracted metadata is structured in JSON, XML, or fed into relational databases or NoSQL stores for further querying. For large repositories, we include batch ingestion pipelines with retry logic, webhook triggers, and version history control. Metadata improves semantic search, allows fine-grained filtering, supports compliance (e.g., PII detection), and enhances document discovery. This service is vital for law firms, media companies, HR departments, compliance teams, and AI applications that rely on high-quality structured data.

Francis –
The metadata tagging automation for documents has revolutionized how we manage our information. The AI/NLP driven extraction and tagging of key entities, topics, and keywords has significantly improved our search, filtering, and compliance efforts. This service has unlocked valuable analytics capabilities and made our documents much more accessible and usable.
Yemisi –
Our organization has seen a significant improvement in document management since implementing the metadata tagging automation. The AI/NLP capabilities have streamlined our workflow, making it much easier to search, filter, and analyze critical information. Compliance and overall efficiency have improved noticeably.
Boshrike –
This IT service for metadata tagging automation has significantly improved our document management. The AI/NLP driven extraction of key information has unlocked powerful search and filtering capabilities, making it easier to find specific documents and analyze large datasets. This has streamlined our workflows and strengthened compliance efforts, proving to be a valuable asset for our organization.
Talatu –
The metadata tagging automation service has significantly improved our document management. The AI/NLP capabilities are impressive, accurately extracting key information that has enhanced our search functionality, streamlined compliance efforts, and provided valuable analytics insights. This service has saved us considerable time and resources.